
On-Device AI Beats Cloud for TTS – Here’s Why
 Mateusz Kopciński•Apr 15, 2026•4 min read
Mateusz Kopciński•Apr 15, 2026•4 min readThe Kokoro comparison
We recently added Kokoro TTS support to react-native-executorch, our open-source library for running AI models on-device in React Native. Kokoro is an 82M-parameter model under the Apache 2.0 license – free to use commercially, including the model weights.
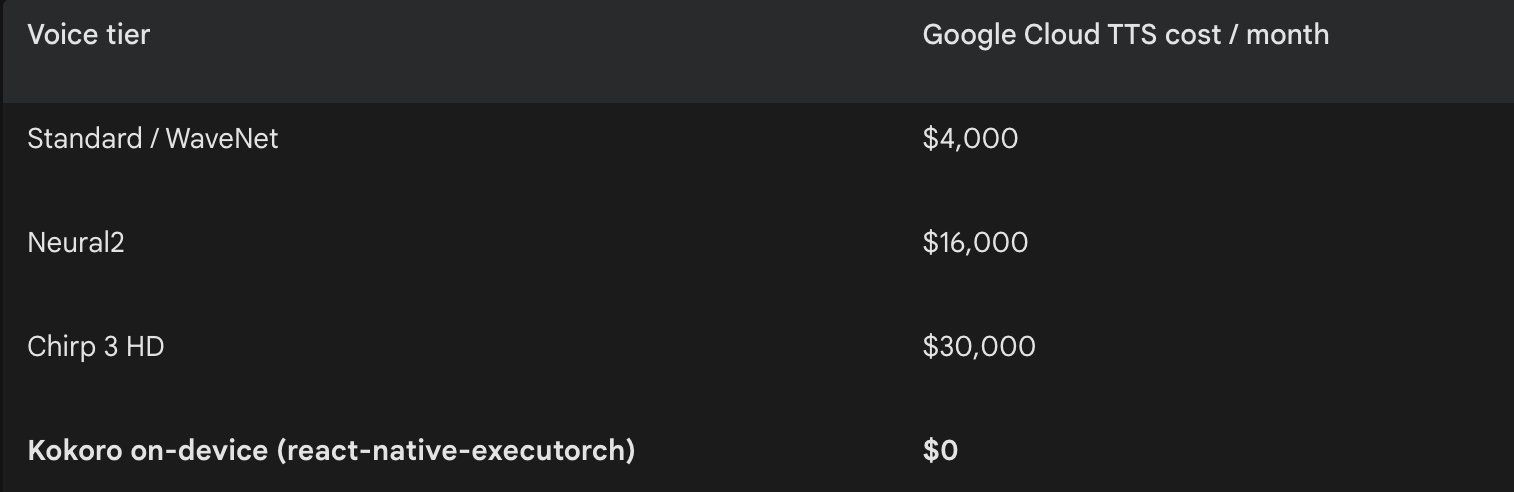 The model download happens once, and only when the user first needs it. After that, every synthesis — whether the user is on a plane, underground, or in a country where your cloud region has high latency — costs nothing and requires no internet connection.
The model download happens once, and only when the user first needs it. After that, every synthesis — whether the user is on a plane, underground, or in a country where your cloud region has high latency — costs nothing and requires no internet connection.
Kokoro's tradeoffs
Integration is simpler than you'd think
import {
useTextToSpeech,
KOKORO_MEDIUM,
KOKORO_VOICE_AF_HEART
} from 'react-native-executorch';
const App = () => {
// Runs 100% on-device. Zero network calls. Zero cost.
const tts = useTextToSpeech({
model: KOKORO_MEDIUM,
voice: KOKORO_VOICE_AF_HEART,
});
const handleSynthesize = async (text: string) => {
const waveform = await tts.forward(text);
// Play or process the audio
};
};Beyond cost
Cost is the argument that tends to cut through in planning discussions, but it's not the only one.
Offline capability is real and undervalued. A TTS feature that requires internet access will silently fail in the subway, in rural areas, on flights, and in emerging markets with unreliable connectivity. On-device inference simply works, everywhere, always.
Latency – a cloud API call involves a round trip to a server — typically 200–800ms depending on region. On-device inference on a modern smartphone can be faster, and more importantly, it's consistent. There's no cold start, no regional latency spike, no degraded performance under load.
Privacy is another dimension, and how much it matters depends heavily on your use case. When TTS runs on-device, the text being synthesized never leaves the phone — not to your servers, not to a cloud provider, not anywhere. For consumer apps that's often a nice-to-have. For apps in healthcare, legal, finance, or personal productivity, it can be a genuine architectural requirement, and in some jurisdictions, a compliance one.
The scaling argument
The cloud pricing model is designed for the early stages of a product, when usage is low and convenience outweighs cost. As you scale, though, per-request pricing becomes a structural cost that grows in proportion to your success. On-device AI inverts this: your infrastructure cost is fixed (the engineering work to integrate it), and usage is free. For features like TTS that are high-frequency and not computationally exotic by modern phone standards, this is a compelling case.
React Native developers in particular are in a good position to take advantage of this shift. Our library react-native-executorch makes it possible to ship on-device AI features without deep expertise in native code or machine learning — the hard parts of model export, runtime integration, and memory management are handled at the library level.
On-device AI won't replace cloud APIs for every use case. Tasks that require massive models, real-time training, or centralized data still belong on servers. But for well-scoped inference — speech synthesis, image classification, language understanding — especially on features that run frequently and at scale, the question has shifted. It's no longer "is on-device AI good enough?" It's "why are we still paying per request?".